Tomás
Gonçalves
Welcome to my online resume!
I'm Tomás, a data scientist and consultant based in Copenhagen. This site gives you a better sense of who I am and what I do beyond the CV.

Let's chat!
This chatbot is trained on my background. Ask me about my work, studies, or projects. Instead of reading through everything, you can just ask!
Demo: KYC compliance Review
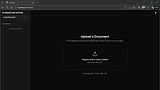
Built a KYC compliance review agent as the primary proof of concept, the kind of document-heavy, judgment-intensive workflow that financial services firms run manually today.
A compliance officer uploads a customer document. The agent reviews it for completeness, consistency, and risk flags, then returns a structured verdict (Approve / Escalate / Refer). No client data ever reaches the model.
This demo runs against two examples:
-
Example 1 - Clean file
-
Example 2 - Incomplete
Disclaimer: This is a proof of concept built independently. It is not in production and has no organizational affiliation.
Passion Projects
SurrogateAI
Problem: The explosion of AI agents and LLMs creates a real problem for European organisations: the most powerful models run on US cloud infrastructure, and feeding them real client data creates immediate GDPR exposure. For financial services firms handling KYC documents, client records, and transaction data, this is not a theoretical risk. It is a hard blocker on AI adoption.
Solution: I built a pipeline that automatically detects and replaces sensitive information (names, financial identifiers, health data, government IDs) with realistic-looking surrogates before anything reaches the model. The LLM reasons over fake-but-coherent data, and the response is reconstructed back to the original values before the user ever sees it. The redaction layer is completely invisible. The pipeline is task-agnostic and can be applied to any workflow that requires an LLM to reason over sensitive data.
Architecture: Redaction and Reversible Anonymization

Demo:
-
2,200+ active listings aggregated daily across 35+ sources
-
Interactive map with price-coded clustering vs neighbourhood median
-
Per-property valuation with good deal, fair market, and overpriced ranges
-
Price history tracking per listing
-
Comparable properties and neighbourhood-level market analysis
-
Best deals table: properties 10%+ below the local median
-
Saved search alerts for new listings and price drops
-
Automatic detection of private sellers listing without agents
-
LLM-powered assistant to explore listings and find opportunities in natural language

Disclaimer: This is a proof of concept built independently. It is not in production and has no organizational affiliation.
Lisbon Real Estate Market Tool
Problem: Lisbon's real estate market has been growing at one of the fastest rates in Europe, prices up year on year, inventory tight, and the best deals absorbed before they are widely seen. I am Portuguese, from Lisbon, and at some point I want to buy a flat back home. Doing that from Copenhagen, with no local network and no agent working in my corner, means I am always a step behind. Most property portals show you what is already in front of everyone else. I wanted to see more.
Solution: I built a full-stack intelligence platform that scrapes 35+ Portuguese property portals daily, deduplicates and normalises the data into a structured database, and surfaces it through an interactive dashboard. The system tracks every listing across sources, detects price changes over time, identifies properties priced below their neighbourhood median, and flags private sellers listing without agents.
Architecture: Automated Scraping and Market Intelligence Pipeline

Academic Projects
Master Thesis: Detecting Refugee-Related Misinformation on Social Media
Context: Misinformation about refugees doesn't stay online. It shapes political narratives, reinforces prejudices, and in cases like the Southport riots and the Springfield pets controversy, spills into real-world violence. Despite the stakes, no peer-reviewed research specifically targeting refugee-related misinformation detection existed.
Project: Built in collaboration with UNHCR, the research question was: how can fine-tuned transformer-based models detect misinformation about refugees on social media? UNHCR already had a hate speech monitoring tool in place and was exploring whether misinformation detection could be added as a complementary function. This thesis was a first step toward making that feasible.
Data: No ready-made dataset existed for this problem, so we built one. We collected and combined 16 misinformation datasets spanning X posts, Reddit, news articles, and fact-checked claims. On top of that, we manually reviewed and labeled 250 refugee-related X posts sourced through Meltwater, creating a validation dataset that didn't exist before.
.png)
Methodology: Two modeling phases. First, benchmarking transformer-based models including ModernBERT, Llama 3.1, Gemma 2, and DeepSeek across four dataset variations. Second, taking the best-performing model and using it as a teacher in a knowledge distillation process, training a smaller ModernBERT-large student model to replicate its behavior at a fraction of the size.

Results: The distilled model reached 0.772 accuracy and 0.832 F1-score, matching the teacher at 1/20th of its size. Strong on emotionally charged language, weaker on sarcasm and negation.
Curious about the full research? Read the thesis here.
Other Academic Projects
Skin lesions classified as benign, malignant, or undetected using SVM and CNN models to compare accuracy and efficiency in automating melanoma diagnosis from image data.
Melanoma Detection Analysis
Movie Genre Classification Models
Can a model read a plot summary and guess the genre? Using BERT, RNN, and Naive Bayes on IMDb data, I tested how well NLP can replace manual genre tagging.
Portugal GDP Forecasting
COVID-19 hit Portugal's GDP hard. I used ARIMA and ETS models on Federal Reserve Economic Data (1995 to 2023) to measure the impact and forecast recovery trends.
Experience
AI & Data Consultant
[EY]
Remediation project for large Danish Bank: Part of an external remediation engagement addressing incorrect penalty interest on housing loans.
-
Translated legal and regulatory requirements into data-driven calculation logic.
-
Analyzed and transformed complex loan and payment data using Python and SQL to enable accurate remediation calculations.
-
Collaborated with legal, business and technical SMEs and supported quality assurance deliverables.
Member of Proof of Concepts delivery team: Building data and AI-enabled prototypes to showcase capabilities and grow the client project portfolio.
Copenhagen, DK
2025 - Currently
Data Analyst (SA)
[Everllence]
Contributed to the Mail Sorting Automation project, utilizing Machine Learning (ML) and Natural Language Processing (NLP) techniques. Developed and trained the WHAT model to classify emails into categories, enhancing operational efficiency and accuracy.
Designed and deployed a Power BI dashboard for Robot Process Automation (RPA) initiatives, resulting in an automation value of €2.1 million and saving 26,000 manual hours. This tool facilitated clear and quantifiable insights into the financial and operational benefits of automation for stakeholders.
Architected and maintained SQL databases, implementing best practices for data integrity, security, and accessibility
Copenhagen, DK
2023 - 2025
Technology Consultant
[KPMG]
Provided expertise and guidance on IFRS-17 and Solvency II regulations, enhancing compliance processes and increasing report accuracy by an average of 23% across several major financial institutions.
Collaborated with clients to optimize their data management systems, achieving a 12% reduction in data handling time and minimizing processing errors, thereby boosting operational efficiency and improving data reliability.
Lisbon, PT
2022 - 2023
Language Skills
Portuguese
Native Language
English
Level C1 Certified
Spanish
Level A2 Certified
Danish
Level A1 Certified
Skills
Certification
Databricks Academy - Databricks Fundamentals Accreditation
Technical Skills
Programming Languages: Python, R, SQL
Data Platforms: Databricks
AI & LLM Tools: AI Agents, Prompt Engineering, LLM-assisted Development
Data Analysis: Pandas, NumPy, Excel
Machine Learning: Scikit-learn, TensorFlow, Keras
Data Visualization: PowerBI, Tableau, Matplotlib
Tomás Gonçalves

© 2026 by Tomás Goncalves